每天拆解一个AI知识点:Token(词元)
👉 什么是Token?
Token 是大语言模型在处理文本前,把文本切分成的一种“最小语言单位”。切分后的 token 会被映射为一个数字编号(ID),供模型理解和运算。
🎈Token 可以是:
1️⃣ 单个字符(如英文的 "a"、中文的 "字")
2️⃣ 一个完整的词(如英文的 "cat"、中文的 "模型")
3️⃣ 词的一部分(如英文单词 "happiness" 可能被拆分为 "happy" + "ness",中文的 "巧克力" 可能被拆分为 "巧" + "克力")
4️⃣ 标点符号或特殊符号(如 "?"、"\n")。
[种草R] token生成过程示例:
1️⃣ 先分词:例如,Unhappy → "Un" + "happy"(不同模型的分词规则可能不同)
2️⃣ 再编码:"Un" → 12345,"happy" → 42(具体映射成的数字取决于模型的词表)
👉 为什么需要Token?
大模型本质上是“数学工具”,只能处理数字,无法直接理解文字。Token 的作用是将文本标准化为模型能计算的数字单元,相当于在人类语言和机器计算之间架了一座桥。
🌸为什么不能直接处理文字?
1️⃣ 语言太灵活:人类语言有无数种表达方式(如缩写、错拼、方言),直接处理原始文本对计算机来说就像读天书。Token 通过固定规则切分,将混乱的文本转化为结构化数据。
2️⃣ 拆分后更易学习:比如,整词 "unbelievable" 对模型只是一个陌生符号,拆成 "un" + "believ" + "able" 后,模型能复用已知部分(如 "un" 表示否定,"able" 常见于形容词),举一反三。
3️⃣ 节省资源:共享子词,从而减少词表大小,降低存储和计算开销。例如,"ing" 对应所有动词进行时,把它作为一个独立的token,就无需在词表中存储所有表示进行时的动词。
👉 Token在大模型里怎么用?
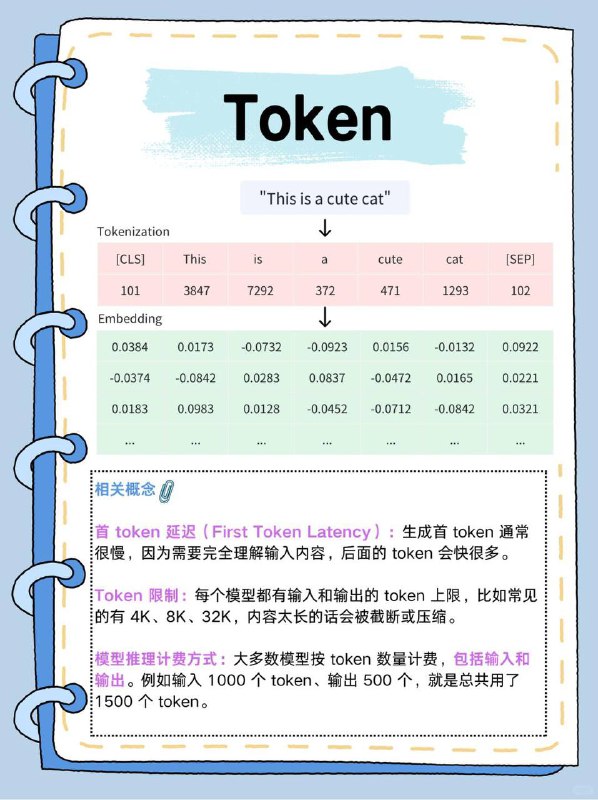
1️⃣ 输入文本(提示词)会被切分成 token,每个 token 是模型词汇表里的一个编号。
2️⃣ 每个 token 会映射成一个词嵌入向量(embedding),用来表示它的语义。
3️⃣ 模型通过计算这些词嵌入之间的关系,理解上下文,并推理生成下一个 token。
4️⃣ 输出的 token 再被转换回文字,生成自然语言结果。